Posts Tagged r
R的错误处理机制
Posted by qiuxing in computing, statistics on 7月 30, 2011
基本用法:在自己写的函数里调用 warning("a message.") 或者 stop("a message.") 两者的区别是 warning() 不会中断你的函数, stop() 则会。
mysqrt <- function(x) { if (x>0) { warning("Only the positive square root is computed.") return(sqrt(x)) } else if (x<0) { stop("x must be a positive number.") } else { return(0) } }
大部分时候,警告/中断机制都有它存在的意义。但有时候我们要做1000次simulation, 其中要有一次 glm() 不收敛了可能整晚上的simulation就中断了。这时候怎么办?
解决方法是 tryCatch() . 写一个 inline 函数在警告的时候跑,再写一个 inline 函数在中断的时候跑。用 tryCatch() 来做这种特殊的分支。
newsqrt <- function(x) { tryCatch(mysqrt(x), warning=function(msg) { print(paste("Caught warning message:", msg)) return(-x) }, error=function(msg) { print(paste("Caught fatal message:", msg)) return(NA) } ) }
cacheSweave使用简介
介绍
我假设你了解并会使用Sweave. 如果你不知道Sweave但知道并会用R和LaTeX,我强烈建议你学一下Sweave. 一个Sweave文档基本上是LaTeX文档和R code的组合。我现在几乎所有的consulting的报告,一些教课的文档等都用Sweave来写了。 Emacs对Sweave(通过noweb-mode)的支持也还算可以。
就因为Sweave是联合体,每次编译Sweave都得要重新跑一遍里面的R code. 简单的consulting当然没有什么,但有些加了simulation的东西这样每次编译要重新跑就不现实了。cacheSweave/pgfSweave就是为了解决这个问题而写的。
安装
- 先保证你的R版本够新(R>=2.12). 如果你嫌用Ubuntu自带的R太老,你可 以加CRAN上的deb repository. 具体请google之。
- 接下来你只要在R里
install.packages(c("filehash", "cacheSweave"))一下即可。 filehash必须手动装(这应该 是cacheSweave的一个bug)。 - Google并下载
Sweave.sh, 放到binary PATH里头。
基本使用
- 正文例子. 基本上,就是在需要计算但不需要output verbatim/tex的code chunk上加参数
cache=TRUE. 当然,最好用setCacheDir(cache)设一个cache directory, 否则在你的working directory里会生成无数垃圾文件夹。 - 命令行用法:
Sweave.sh -c foo.Rnw
第一次跑当然不会变快,但第二次跑就应该几乎不花什么时间了。
Linux下怎么管理,升级R的libraries
Posted by qiuxing in computing, statistics on 4月 7, 2011
- 能用APT之类的发行版自带工具升级就用这个工具好了。目前Ubuntu里面大约 有150个包,大部分时候就可以满足需求了。
- 如果要自己装一些包,最好设置一个固定的path. 方法是设置一个叫做
R_LIBS_USER的环境变量。比如说我的.bash_profile里头有这么一句:export R_LIBS_USER="${HOME}/local/lib/R"这样 R 就会把包装到这个目录下,第一不用root权限,第二你以后管理起来也方便。
- 每次用
install.packages("foo")的时候R都会问你选 CRAN mirror对吧? 要想让它用一个固定的也不难,在你自己的用户根目录下创建一个文件叫做.Rprofile, 在里面写上:r <- getOption("repos") r["CRAN"] <- "http://website/cran/" options(repos = r) rm(r)顺便说一下,每次你启动R, 它第一件事就是去读这个文件的内容。所以比如 说你自己写了一个顺手的小函数什么的都可以放在这里,用不着专门去打一个 包了。
- R的升级命令是
update.packages(). 但这个命令会试图升级你所有的包, 包括系统安装你没有权限也不想改动的。所以我都用这个命令升级:update.packages(lib.loc="/path/to/my/lib/R", checkBuilt=TRUE)
“checkBuilt=TRUE” 的意思是即使某个包的版本号为最新,但如果它是在一个 老版本的 R 环境下编译的那就重新编译;
lib.loc变量,顾名思义,就是 说只升级这个目录下的包。 - 删除一个包。你可以直接去其目录裸删,也可以用
remove.packages(c("pkg1", "pkg2")) - 偶尔有在CRAN 上找不到的包,只有一个zip或者tarball的形式。用以下命令安装:
R CMD INSTALL --library=/path/to/my/R/lib foo_0.76.tar.gz
自己编译安装最新版的ess
我一般不怎么动Ubuntu系统,主要是嫌麻烦。当年玩gentoo的时候所有的包都要本地编译,好玩是好玩,但是太费时费力了。现在用二进制系统就是图歌省事。
但凡事总有例外。我是一个emacs爱好者,所以平时用的都是开发版的emacs (现在得用那个bazaar来下开发版的源代码)。ESS也是这样,属于天天要用的,我还是希望自己编译最新版本。当然,能够原则上尽量服从Ubuntu/Debian的规则那还是好的。ESS比较贴心的地方在于它的make file里头直接定义了生成deb包的规则,所以我只需要做这么几样事情:
- 下载解压源代码(目前稳定版为5.13);
- 到它的dir下跑这个命令:make builddeb
- 上面的那个命令会在source dir的上一层目录生成一个deb包,用dpkg来安装之:sudo dpkg -i ess_5.12-1_all.deb
就这么简单。
R: 列出一个package里所有的函数
其实不光是函数,也包括了别的一些objects. 另外,一个package还有一些内部使用的函数未必都让你import.
方法一:library(help = foo),不过严格来讲这个不算。
方法二:ls(“package:foo”),没有任何的解释,就是列出所有的objects
方法三: lsf.str(“package:foo”),这个我觉得最好。
另外就是关于内部函数。万一你看了它的源代码,想调用它的内部函数怎么办?或者你自己写了一个package, 想细调什么函数可以被用户看到什么看不到怎么办?
答案是改一下源代码的一个叫做NAMESPACE的文件:
export(func1)
export(func2)
….
这些命令决定了什么函数/objects可以被用户看到。
ROC分析当中的AUC和Mann-Whitney U statistic的关系
Posted by qiuxing in statistics on 1月 2, 2011
Receiver operating characteristic (ROC) curve 是在做two group supervised learning非常常用的一个工具。而area under curve (AUC) 又是最常用的一个表述一条ROC曲线的最常用的统计量。
为了更好的说明问题,我们要用到以下这个简单的例子。
- 设我们有
个数据点,可以分成两个组。 第一个组有
个数 据点,第二个组有
个。
- 每个点我们知道两种信息:一个(连续的)观察值,记为
, 一个就是 它的分组,用”0″(第一组)和”1″(第二组)来代表。
ID X_i Group 1 0.11 0 2 0.56 0 3 1.13 1 4 2.14 0 5 2.29 1 - 举个例子,假设这两组分别对应于”Normal”和”Disease”。我们希望能从我们 观察到的这5个
我们 判断第
个数据点为 “Disease”, 反之则为 “Normal”,这里
是一个 可以调整的cutoff point。
显然,在实践中大部分时候我们不可能用这种方法找到 完美 的分类。大一点 的c值就意味着更大可能把本来有病的人误诊为没病(type II error or false negative),但小点的c又会导致一些本来没病的人被误诊为有病(type I error or false positive)。这里的type I/II error是由实践问题的性质所决 定的,光从数学的角度来讲它们完全可以互换。统计上我们一般用false positive rate(记为 



注意,搞工程的人一般不用false positive/negative rate这两个术语,而是习惯用 1-specificity (等于
在 R 里我们可以用如下命令来做ROC分析,计算AUC:
library(ROCR) observations <- c(0.11, 0.56, 1.13, 2.14, 2.29) groups <- c(0, 0, 1, 0, 1) pred <- prediction(observations, groups) perf <- performance(pred, "tpr", "fpr") plot(perf, xlab="1-Specificity", ylab="Sensitivity") ## Wilcoxon rank-sum statistic == 5 wilcox.test(observations[groups==1], observations[groups==0]) ## AUC == 5/6, or U/(n1*n2) performance(pred, "auc")@y.values[[1]]
事实上,AUC和Mann-Whitney U statistic基本上是等价的: 
之所以有这样的关系,是因为计算AUC的时候我们可以把要求的面积沿着x-轴分成
从下面这张图(虚线是我自己加的)看我上面说的关系就很清楚了:
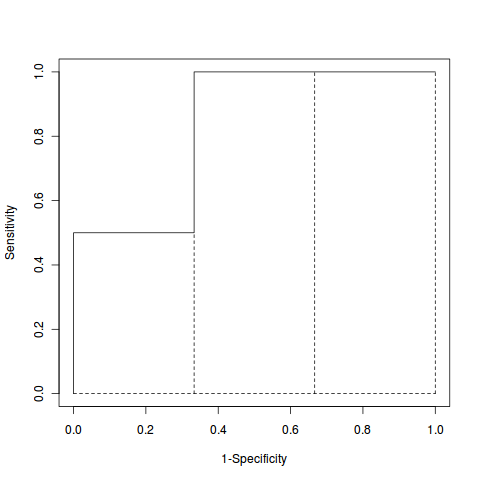
计算一个ROC Curve的AUC
有了这个关系,我们很容易就能算出来AUC:
其中 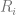
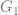


另外还有一个等价,但更加深刻的基于代数的证明。人们很早就知道Mann-Whitney U或 者Wilcoxon rank-sum statistic是连续单调变换群的极大不变统计量(maximal invariant statistic)。换句话说,以下两个条件成立:
- 如果我们例子里的全体
个X都被转换成了
,其中
是一个连续单调函数,那么通过
算出来的
或者
还是 原来的值。(the invariance property)
- 如果另外还有一组数据
的
求出的值,那么必然存在一个 连续单调变换
, 使得
.
而我们很容易通过变量代换来证明AUC也满足这两个性质。所以它们必然存在一一对应关 系和等价的假设检验/classification的判别法。
事实上,不仅仅是sample version的AUC有这个性质,连population的AUC,定义为 
查看一个R session都load了什么packages
用这个函数:
sessionInfo()
最新版的Google Chrome有了内置的PDF reader
一则短消息,最新版的Google Chrome for Linux有了内置的PDF reader和最新的flash player,效果比firefox + 那两个插件要好很多。Adobe和Google看来是准备一起合作了。注意,是chrome而不是那个开源的chromium. 我估计是因为有些代码许可跟GPL冲突了。
最近学到的R的一些技巧
Posted by qiuxing in computing, statistics on 10月 18, 2010
前些时候和我一个打羽毛球的姐们一起做一个项目,要求处理一些本质上是小电影的数据。我现在算是发现,类似于imaging, movie, time course之类的”非传统”的数据分析现在越来越成为统计分析的主流了。
为了她这个项目,我决定写一个小package。出于练手的考虑,我决定采用面向对象编程,以下就是一些刚刚学到的心得。
-
生成一个叫做”movie”的类:
setClass(Class="movie", representation(tmin="numeric", tmax="numeric"), prototype(tmin=1), contains = "array" )这里面Class就是新的类的名字,contains是指的从array类继承而来,representation里头的两个值叫做slots,以后可以用amovie@tmin, amovie@tmax来获得。prototype相当于default value.
-
有了一个类,我们可以定义一个强制检查consisitency的函数:
validity.movie <- function(object){ if (length(dim(object)) !=3 ){ return ("A movie object must contain two spatial dimensions and a temporal dimension!") } else if (dim(object)[3] !=object@tmax - object@tmin +1 ) return ("tmax/tmin do not match the length of time.") TRUE } setValidity("movie", validity.movie)这个检查函数所做的就是要求该array必须是三维,而且最后一维(代表时间)的长度和tmin/tmax必须一致。
-
有了这个新的类,我们可以定义单独作用于此类的一些generic function:
setGeneric("GetTlen", function(object) standardGeneric("GetTlen")) setMethod("GetTlen", "movie", function(object){ object@tmax - object@tmin + 1 })上面的代码生成了一个新的generic function “GetTlen”, 当它作用于movie的时候就给出这个movie的时长。其实我们还可以为这个新的类写一些非常标准的generic function, 比如说show/plot等等。
- 其它的技巧,暂时还没用上。等以后一边学,一边写。
除了OOP以外的心得:
- =R=的多维非参数回归的选择似乎不多(也许这不是=R=的问题)。看来看去,对付大型数据(我的一个movie object的维度是512x512x150 = 39,321,600个data points,占用300多兆内存)似乎还就只有 fields package提供的kernel smoothing的几个函数能handle. 以后我可以试试看gam,但是gam模型假定了一些线性性质,真正的数据未必有。至于loess(lowess), spline之类的速度太慢基本上完全不能用了。当然了,一个full rank的三维spline regression的变量数量可以是惊人的。所以,也许gam之类的半参数回归是唯一可行的办法。
- 做多维的clustering (unsupervised learning), kmean()的效率很高,高到让我吃惊的地步。Mclust则基本不能用。暂时还没实验别的比如说svn.
- GCV当然是标准的选择smoothing parameter的方法。但对于39M个数据点,leave-one-out CV是不可能的。我发现怎么所有的package里都没有比如说10-fold CV之类比较现实一点的方法?不过,手动写这么一个程序到也不难。
ESS (emacs speaks statistics) 有关的设置
Posted by qiuxing in computing, emacs, statistics on 10月 5, 2005
.emacs_ess.el:
和ESS(emacs speaks statistics)有关的设置。写foo.r的时候它会自动调用这个
mode。ESS的完整文档参见:
需要注意的是ess-myfor-loop,这是一个自己写的emacs function的例子。
.emacs_face.el:
关于字体的设置。其实通过emacs的菜单来设置更加容易。这些是老的设置,出于
历史原因保留了下来。
需要注意的一点是emacs的色彩在terminal下面比较单调,所以特别浅的颜色看起
来很不好看。我把那些浅色调都替换成了深色调。
.emacs_tex.el:
(setq TeX-source-specials-mode 1)
你应该通过C-c C-c来编译LaTeX文件,之后可以通过同样的命令来调用xdvi查看
结果。这个选项选上之后xdvi显示的是你目前的那一行LaTeX命令所对应的文件。
在xdvi里头用control 鼠标点一下,emacs就能够回到这个文件所对应的那一行
TeX代码。
(add-hook ‘LaTeX-mode-hook ‘LaTeX-math-mode)
(setq LaTeX-math-abbrev-prefix ‘";")
一个AucTeX的子模式,快速输入希腊字母:’; a’就等于\alpha,; b等于\beta等
等。如果需要输入’;’本身的话:两下;;就出来了。
(add-hook ‘LaTeX-mode-hook
‘(lambda ()
(gnuserv-start ())
(add-to-list ‘TeX-command-list
(list "view-pdf" "xpdf %s.pdf"
‘TeX-run-command nil t)
)
(add-to-list ‘TeX-command-list
(list "pdf" "dvipdfm %s"
‘TeX-run-command nil t)
)
)
)
这一段的意思是把"pdf"和"view-pdf"两个命令加入到C-c C-c的命令列表中去。
这样你就可以通过C-c C-c pdf来一步生成pdf文件,C-c C-c view-pdf来查看
pdf文件(前提当然是要安装xpdf)。
(setq latex-block-names ‘("theorem" "corollary" "proof" "lemma" "proposition"))
告诉emacs这几个东西都是合法的enviroments (通过C-c C-e输入environment)。
;;;;;;;;; RefTeX, BibTeX stuff ;;;;;;;;;;;;
(add-hook ‘LaTeX-mode-hook ‘turn-on-reftex)
(setq reftex-plug-into-AUCTeX t)
;;(setq bibtex-maintain-sorted-entries t)
(add-hook ‘reftex-mode-hook
‘(lambda ()
(define-key reftex-mode-map "\C-cc"
‘reftex-citation)
)
)
(add-hook ‘bibtex-mode-hook
‘(lambda ()
(define-key bibtex-mode-map "\C-c\C-ea"
‘bibtex-Article)
)
)
这两个东西(reftex-mode,bibtex-mode)是非常powerful的索引/标记管理系统,
参看以下说明:
http://staff.science.uva.nl/~dominik/Tools/reftex/reftex.html
http://cmtw.harvard.edu/Documentation/TeX/Bibtex/Example.html
http://www.ida.ing.tu-bs.de/people/dirk/bibtex/bibtex.el/doc/bibtex_toc.html
;;;;;;;;; Font faces ;;;;;;;;;;;;
(add-hook ‘LaTeX-mode-hook
‘(lambda ()
(set-face-foreground ‘font-latex-title-1-face "magenta")
(set-face-foreground ‘font-latex-title-2-face "magenta")
(set-face-foreground ‘font-latex-title-3-face "magenta")
(set-face-foreground ‘font-latex-sedate-face "magenta")
)
)
调整字体颜色
