Archive for 2011年1月
Emacs 中文编码/转码
Emacs 22版之后对中文的支持就已经很好了,大部分时候它都能够正确的自动认出中文编码。但偶尔也有不灵的时候(一般是一种编码里有几个错误字符)。这时候我们可以手动强制它重新编码:C-x RETURN r (Elisp函数名:revert-buffer-with-coding-system), 然后选一个合适的编码,比如说UTF-8, Chinese-GB (等于GB2312)等等。
你还可以用Emacs来转码。比如说从gb2312转成unicode:
- 打开GB2312的文件。
- 如果编码不对,用上面的命令先弄成正确显示。再检查一下,看看有没有错误编码(一些奇怪的数字)。
- 设定存档,文件名的编码:
C-x RETURN f,C-x RETURN F。

在Ubuntu 10.10 (64bit)上安装fuego
fuego是一个下围棋的人工智能程序。据说棋力比gnugo好,尤其在小棋盘上。但这个程序目前还不在Ubuntu的官方软件仓库里。
说是安装fuego, 其实可以作为一个比较典型的在Ubuntu上安装外来软件的范例。
- 先安装这两个软件:
sudo apt-get install checkinstall libboost-all-dev
- 下载并解压fuego的源代码包。
- 用如下命令configure/make
./configure --with-boost-libdir=/usr/lib64/ --prefix=/usr
稍微解释一下,–with-boost-libdir=/usr/lib64/ 只是这个软件必须。那个 –prefix=/usr 则是绝大部分软件的标准安装路径。
- 用checkinstall将刚刚编译好的包转成一个标准的Ubuntu软件包(deb包)并安装
sudo checkinstall -D make install
然后你要回答几个问题。比较重要一点的是那个”Requires”, 这里你应该选
libboost-thread1.42.0 (>= 1.42.0-1), libboost-filesystem1.42.0 (>= 1.42.0-1), libboost-system1.42.0 (>= 1.42.0-1)
为什么不直接在第2步之后就用标准的make install来安装?答案是那样你不大好管理。通过制作一个Deb包,你就可以用Ubuntu本身的软件管理方法(apt-get remove, 或者那个图形化界面)来删除这个软件。而且,你要是愿意的话还可以和别人分享这个包,省得别人还要编译。
如何对多个文件执行字符替换(search/replace)
答案是Emacs。
- 用dired选文件。这又有两个变化:M-x dired 或者C-x d比较像ls,就是这一层的文件;M-x find-dired则包括所有的子目录,也就是说像find。不管用哪个,出来了文件之后你可以一个一个的选(按m键选,u键勾掉),也可以用%m组合来选符合文件名正则表达的文件。更强大的功能是%g, 对文件的内容执行正则搜索。
- 对选好的文件执行字符替换。热键是Q或者M-x dired-do-query-replace-regexp。emacs会一个一个的问你要不要替换。y选替换,n不替换,C-g退出,大写Y则等于对所有之后的问题回答y(Emacs version >= 23.0)。
- 弄完之后还要存盘。你当然可以一个buffer一个的存盘,但如果开的文件多了这个方法就比较麻烦了。解决办法有两个,一个简单点的是C-x s (M-x save-some-buffers); 另外一个cool一点的办法是用ibuffer: M-x ibuffer调出ibuffer,然后用*u来选中所有未存盘的buffers,S全部存盘,D全部关闭。
Emacs is the ONE, TRUE editor.
本文基本上参照李殺网的攻略:
R: 列出一个package里所有的函数
其实不光是函数,也包括了别的一些objects. 另外,一个package还有一些内部使用的函数未必都让你import.
方法一:library(help = foo),不过严格来讲这个不算。
方法二:ls(“package:foo”),没有任何的解释,就是列出所有的objects
方法三: lsf.str(“package:foo”),这个我觉得最好。
另外就是关于内部函数。万一你看了它的源代码,想调用它的内部函数怎么办?或者你自己写了一个package, 想细调什么函数可以被用户看到什么看不到怎么办?
答案是改一下源代码的一个叫做NAMESPACE的文件:
export(func1)
export(func2)
….
这些命令决定了什么函数/objects可以被用户看到。
Lame确实比ffmpeg快很多
手头上有一个巨大的mp3文件(一本有声电子书),将近1G,时长大概是18个小时左右。我的大妈手机(HTC Aria)拒绝播放这么大的文件。我看了一看,发现这个文件的编码太过分了,居然用了128k的bitrate! 有声电子书要32k就够了。
于是我就去找工具来转换这个bitrate。
- 首先用GUI工具。以前自己制作手机铃声用过audacity,应该说界面确实做的比较友好,功能也特别多。好,启动audacity,打开这个文件。等了10分钟还没完,报错说硬盘不够用了。我看了一下
~/.audacity1.3-myname, 吓了一跳:居然用了14个G的硬盘当它的什么project directory!!! 显然,audacity完全不能对付这种大小的声音文件。 - 下一步就是试验命令行工具。这下学乖了,先拿一个5M大小的mp3文件做实验。先试了一下ffmpeg:
ffmpeg -i input.mp3 -ab 32k -ac 1 output.mp3
解释一下,
-ab 32k指定了audio bitrate,-ac 1指定了audio channel为一个,也就是单声道。time给出时间,大概是17秒的样子。 - 接下来试lame:
lame -b 32 -m m input.mp3 output.mp3
这里
-b 32当然指的是bitrate=32k,-m m指的是mode = monaural。结果我看了一下,压缩比,声音效果都差不多,但只用了不到8秒!
最后,那个将近1G的大文件被压缩成了246M,用时26分钟左右。
壹基金获公募身份 未来募捐平台将向全国发展_资讯频道_凤凰网
评论:这看起来很小的一件事情很可能会是未来NGO在中国全面铺开的一个序曲。
壹基金获公募身份 未来募捐平台将向全国发展_资讯频道_凤凰网
微软要出ARM版的Windows了 — Linux阵营的重大利好消息
如果微软没撒谎的话,Windows 8会有一个ARM port,而这个玩意和现在的Windows CE不一样,它的内核和绝大部分code base会和它的big brother, 正常桌面版本的Windows一样。
从Redmond的角度来讲,这个举动非常正常。毕竟,移动和嵌入式装置才是未来的增长点,普通的PC市场已经“成熟“了。而且,苹果搞一个操作系统,多个硬件平台ports也有好多年了,效果很好(好到黑莓的整个决策层彻底被骗,陷入空前被动),也等于为它作了一番市场调查。
从长远来看,我认为这一举措要么会是微软白砸钱以完全失败而高中,要么就是中短期成功,但长期来讲很可能会给整个Linux社区带来巨大的利益。原因如下。
- 和Apple当年从PPC转向x86平台不同,ARM没有x86芯片的计算速度快(ARM的优势在于简单,便宜,省电),所以单搞一个类似Rosetta那样的模拟器是不行的,效率上跟不上。任何一个像样的大型软件都必须重新编译。另外一点苹果比微软牛的地方在于他们比微软还要恶霸,软件硬件通吃不说,而且苹果当时也包括现在都牢牢掌握其生态系统的核心决策权力,再加上船小好掉头,他们要让所有(其实也没多少)写苹果软件的公司重新编译,它们再不满意最后也都从了;他们还决定要让人编译成双二进制代码(同时能在PPC和x86上跑的fat binary),马上这个就成为行业标准;至于苹果的“上帝“,用户们–苹果今天说PowerPC是人类文明最高的体现这帮人就会说是啊x86简直就是一坨屎,明天说其实还是Intel的x86好同样的一帮人马上又给自己找原因找寄托证明其实自己一直都觉得x86才代表了先进的生产力。微软可没有这么忠心耿耿的客户群和俯首帖耳的第三方软件供应商。所以微软的这种转型要比苹果困难的多。
- 再来讲一个更加根本的问题。一个普通用户为什么要选Windows? 答案多半是因为几乎所有的软件都是为Windows写的,而不是说Windows那个界面本身有多了不起。现在张三买了一台ARM+Win8的最新最酷的平板电脑回家,发现他从电驴上当下来的盗版Office没法装了;他一上网,又发现播放一个视频要插件,这个插件当然也是x86才能用的;最后他说老子不上网不用Office了,老子接个摄像头打印机照相机什么的当家庭娱乐机用好了,结果发现所有的硬件驱动也都不能用。这样的Windows有什么用?还不如Linux或者Android,至少你知道那是个不同的东西有不同的装软件的模式。销售这种硬件的厂家也会很头疼,要不停的接客服电话跟他们讲“桌面Windows“和“移动Windows”的区别,要解释很多东西你就是装不了—-不是微软的责任而是第三方供应商不肯“重新编译一下“。但从Linux论坛上用户的提问来看,用户们可不会买这个帐,他们宁愿相信不能跑某个应用程序一定是操作系统的错。
- 我们现在假设前面的问题都得到了解决,作为行业老大的微软又一次赢了,ARM+Win8最终取得了成功。那时几乎所有的软件包括中国的网银们都开始写portable的程序,并且会搞cross compilation了。我认为这个前景对所有的用户,当然也包括Linux用户们来讲是非常有利的。因为很多厂家不愿意为Linux写程序的原因是porting成本太高。很少有人和钱包(公司的或者是个人的)过不去,即使Linux只有1%的市场份额那也是几千万人的市场,比很多国家都大了。如果一个软件的源程序本来就写得比较好,易于port,只要很小的改动就能在另外一个操作系统上跑,我相信大部分厂家都会愿意开发Linux, OSX, 等等的程序。而这是一个良性循环,因为应用程序多了,用非主流操作系统的人也会多。这里多说一句,从portability的角度来讲,其实微软自己的代码还真不算差。如果我没记错的话,最早的Windows NT就是同时在x86和MISC上开发的,后来的Alpha,Itanium ports也都还不错。关键是第三方Windows程序员的水平太烂了,这里又以中国当时随着盗版Windows和计算机考级成长起来的一代人为甚。
- 还是假设ARM+Win8成功了。但这个成功来自另外一种(说不定更大的)可能,就是基于网络的应用终于成了主流了,Java/.Net/JavaScript/。。。等等不需要cross compilation的程序最终赢得了胜利,那么当然底层你用什么CPU也就无所谓了。这件事情对于所有非主流操作系统用户来说是一个更大的利好消息:因为模拟一个.net解释器的成本比模拟一个Windows要小太多了。如果当真有一天应用程序都在云端了那谁还会在乎本地操作系统是Win8还是Android还是Haiku?
几年前Firefox刚刚兴起(出1.0版左右)的时候我在MITBBS Linux版曾经说过假如Firefox真的成了一个让人不可忽略的浏览器,那么事后看当年netscape决定开源恶心一下微软就是Linux一个起死回生的重大事件,搞笑一点的说就是自从发明了烤面包机以来最好的事件。
为什么?浅显一点的说是因为有了一个好使的主流浏览器Linux才有了可用性(想像一下如果你现在用Linux但只有lynx上网,你还能用Linux当桌面吗),才能够保住现在的1~2%的市场份额;深刻一点的说是因为计算机的未来属于网络,而一个开源,跨平台的浏览器参与竞争能保证网络相关的标准不会被一家垄断,从而让因特网继续成为创新,开放的平台,才会有google, facebook, twitter在微软垄断了桌面系统,击溃了网景之后仍能成长起来,改变我们这些现代人社交,分享信息的方式,甚至改变我们对什么是社交本身的认识。
乱七八糟的几个小技巧
- Bash支持arrays, 有时在script里做循环什么的还有点用。用法是这样子的:
List1=( foo bar 123 hello world ) for i in {1..5}; do echo ${List1[$i]} done - 比较新的Bash (>=4.0)还支持associate array,也就是R里的named list,python里面的dictionary,用法这样:
declare -A List2 List2=( [foo]=hello [bar]=world ) echo ${List2[foo]} echo ${List2[bar]} - 搞并行运算的一个前提是nodes之间能通过passwordless ssh进行通讯。passwordless ssh本身并不难,但我前两天老革命也碰到了新问题:不知道要用ssh-add来添加密钥。我记得很久很久以前,ssh是不需要ssh-agent来传递密钥的,而现在的”modern” Linux distros什么东西都是越做层数越多越复杂,sigh。
- ipython用过,但从来都只用来跑python scripts. 到前两天才知道如果用ipython -p sh来启动的话基本上它可以当一个shell用,也就是说shell能看到的命令它都能看到。
In China, Gang-Run Illegal Rare Earth Mines Face a Crackdown – NYTimes.com
这几天时间里纽约时报连续登了好几篇关于中国明年起要大幅减少对外出口稀土配额的文章。我觉得最有意思的一点就是这几篇文章的语气和态度的变化。从最初的批评中国搞贸易保护主义并强调美国政府应该通过WTO来调查中国是否又违规了,到这一篇我认为比较客观的强调这个决策背后的保护环境的理念,不说转了180度,至少也是尽量做到了相对平衡的观点。
另外最有意思的是comments。可以看看那些美国人的态度怎么随着文章的腔调的变化。
其一:
China to Tighten Limits on Rare Earth Exports
其二:
Main Victims of Mines Run by Gangsters Are Peasants
其三:
In China, Gang-Run Illegal Rare Earth Mines Face a Crackdown – NYTimes.com.
总的来说,我觉得纽约时报的编辑和读者还算是客观,虽然比较naive一些。这些相对比较客观的介绍开发稀土对中国环境的影响的文章还是能够对一部分美国民众起到教育作用的。
ROC分析当中的AUC和Mann-Whitney U statistic的关系
Posted by qiuxing in statistics on 1月 2, 2011
Receiver operating characteristic (ROC) curve 是在做two group supervised learning非常常用的一个工具。而area under curve (AUC) 又是最常用的一个表述一条ROC曲线的最常用的统计量。
为了更好的说明问题,我们要用到以下这个简单的例子。
- 设我们有
个数据点,可以分成两个组。 第一个组有
个数 据点,第二个组有
个。
- 每个点我们知道两种信息:一个(连续的)观察值,记为
, 一个就是 它的分组,用”0″(第一组)和”1″(第二组)来代表。
ID X_i Group 1 0.11 0 2 0.56 0 3 1.13 1 4 2.14 0 5 2.29 1 - 举个例子,假设这两组分别对应于”Normal”和”Disease”。我们希望能从我们 观察到的这5个
我们 判断第
个数据点为 “Disease”, 反之则为 “Normal”,这里
是一个 可以调整的cutoff point。
显然,在实践中大部分时候我们不可能用这种方法找到 完美 的分类。大一点 的c值就意味着更大可能把本来有病的人误诊为没病(type II error or false negative),但小点的c又会导致一些本来没病的人被误诊为有病(type I error or false positive)。这里的type I/II error是由实践问题的性质所决 定的,光从数学的角度来讲它们完全可以互换。统计上我们一般用false positive rate(记为 



注意,搞工程的人一般不用false positive/negative rate这两个术语,而是习惯用 1-specificity (等于
在 R 里我们可以用如下命令来做ROC分析,计算AUC:
library(ROCR) observations <- c(0.11, 0.56, 1.13, 2.14, 2.29) groups <- c(0, 0, 1, 0, 1) pred <- prediction(observations, groups) perf <- performance(pred, "tpr", "fpr") plot(perf, xlab="1-Specificity", ylab="Sensitivity") ## Wilcoxon rank-sum statistic == 5 wilcox.test(observations[groups==1], observations[groups==0]) ## AUC == 5/6, or U/(n1*n2) performance(pred, "auc")@y.values[[1]]
事实上,AUC和Mann-Whitney U statistic基本上是等价的: 
之所以有这样的关系,是因为计算AUC的时候我们可以把要求的面积沿着x-轴分成
从下面这张图(虚线是我自己加的)看我上面说的关系就很清楚了:
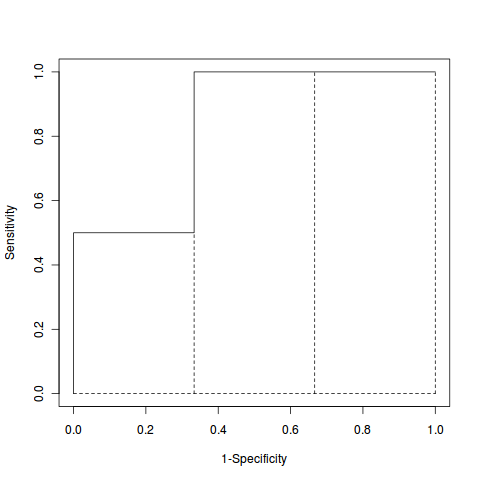
计算一个ROC Curve的AUC
有了这个关系,我们很容易就能算出来AUC:
其中 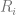
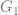


另外还有一个等价,但更加深刻的基于代数的证明。人们很早就知道Mann-Whitney U或 者Wilcoxon rank-sum statistic是连续单调变换群的极大不变统计量(maximal invariant statistic)。换句话说,以下两个条件成立:
- 如果我们例子里的全体
个X都被转换成了
,其中
是一个连续单调函数,那么通过
算出来的
或者
还是 原来的值。(the invariance property)
- 如果另外还有一组数据
的
求出的值,那么必然存在一个 连续单调变换
, 使得
.
而我们很容易通过变量代换来证明AUC也满足这两个性质。所以它们必然存在一一对应关 系和等价的假设检验/classification的判别法。
事实上,不仅仅是sample version的AUC有这个性质,连population的AUC,定义为 
